TinyFish: API de Busqueda Web y Fetch Gratuita para Tus Agentes de Codificacion con IA
TinyFish da a tus agentes de IA busqueda web estructurada y obtencion limpia de paginas gratis. Configuralo con Pi, Hermes, OpenClaw o cualquier agente de codificacion en menos de 5 minutos.
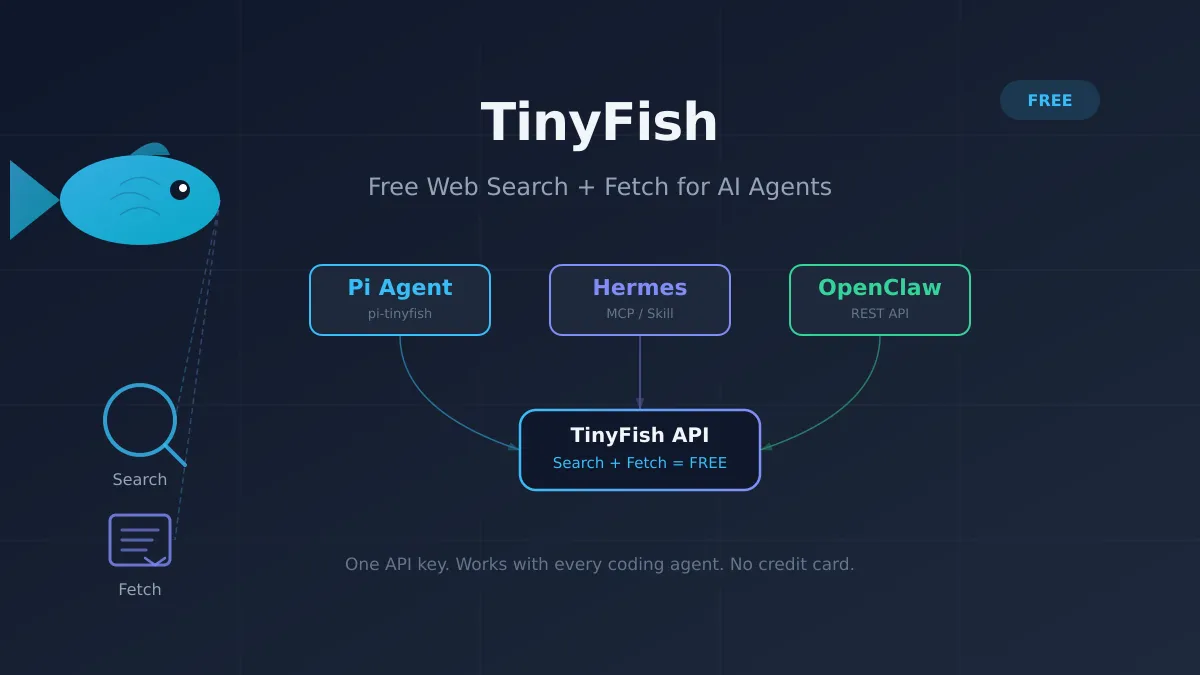
Todo agente de codificacion con IA choca con el mismo muro tarde o temprano. Le preguntas sobre la ultima API de una libreria, una imagen de Docker que cambio su esquema de etiquetado, o un formato de configuracion que se actualizo la semana pasada. Los datos de entrenamiento del modelo se detienen en 2025 (o antes), y o bien alucina o te dice que revises la documentacion tu mismo. No sirve de mucho.
La solucion es darle a tu agente acceso a la web en vivo. Y ahi es donde entra TinyFish. TinyFish proporciona busqueda web estructurada y obtencion limpia de paginas a traves de una sola clave API. Search y Fetch son gratis — sin tarjeta de credito, sin periodo de prueba, solo registrate y adelante.
He estado usando TinyFish a traves del paquete pi-tinyfish en Pi coding agent durante unas semanas. Funciona lo suficientemente bien como para querer explicar que hace, como configurarlo, y por que importa para agentes como Hermes y OpenClaw tambien.
Obtener clave API gratuita de TinyFishLo que cubre esta guia
- Que es TinyFish y como funcionan Search + Fetch
- Configurar TinyFish con Pi coding agent mediante pi-tinyfish
- Usar TinyFish con Hermes Agent, OpenClaw y otros agentes de codificacion
- El TinyFish Cookbook: recetas listas para tareas comunes de automatizacion
- Niveles de precios y limites de tasa
Que hace realmente TinyFish
TinyFish tiene cuatro endpoints, pero solo necesitas dos para empezar:
Search toma una consulta y devuelve resultados JSON estructurados. No es una lista de enlaces azules pensados para ojos humanos — datos limpios y estables en ranking que un LLM puede parsear sin adivinar. Los tiempos de respuesta estan por debajo de 500ms. Puedes pasar pistas de ubicacion e idioma para resultados geolocalizados.
Fetch toma una o varias URLs y devuelve contenido limpio. La pagina se renderiza en un navegador Chromium real (JavaScript, SPAs, todo), y luego se eliminan las barras de navegacion, banners de cookies, anuncios y scripts. Obtienes markdown, HTML o JSON de vuelta. Tu modelo deja de gastar tokens en basura HTML.
Los dos endpoints mas pesados — Agent (automatizacion de navegador en lenguaje natural) y Browser (sesiones CDP raw) — son de pago y consumen créditos. Para uso con agentes de codificacion, Search y Fetch cubren el 95% de lo que necesitas.
Por que esto importa para los agentes de codificacion
La mayoria de agentes de codificacion dependen de los datos de entrenamiento del modelo para cualquier cosa fuera de tu codebase. Eso funciona para patrones estables y APIs bien documentadas. Se desmorona con:
- Lanzamientos recientes — una libreria que publico cambios incompatibles la semana pasada
- Diferencias especificas por version — “esta imagen de Docker todavia soporta ARM64 en v3?”
- Soluciones de la comunidad — el issue de GitHub donde alguien ya resolvio tu problema exacto
- Busqueda de documentacion — leer la documentacion real en vez de adivinar desde la memoria
Darle a tu agente un pipeline de busqueda + fetch lo convierte de “creo que asi funciona” a “aqui esta la documentacion actual, y aqui hay tres issues de GitHub confirmando este comportamiento.”
Configurar TinyFish con Pi coding agent
Pi ya soporta TinyFish a traves del paquete pi-tinyfish. Anade dos herramientas a tu agente: tinyfish_search y tinyfish_fetch. La instalacion es un solo comando.
Paso 1: Obtener tu clave API
Registrate en agent.tinyfish.ai. Sin tarjeta de credito. Copia la clave API del dashboard.
Paso 2: Instalar pi-tinyfish
pi install npm:pi-tinyfishpi install git:github.com/x1any/pi-tinyfishPaso 3: Configurar la clave API
export TINYFISH_API_KEY="tu_clave_api_aqui"Anade eso a tu perfil de shell (~/.bashrc, ~/.zshrc, o ~/.config/fish/config.fish) para que persista entre sesiones.
Paso 4: Usarlo
Eso es todo. La proxima vez que inicies Pi en un proyecto, el agente puede llamar a tinyfish_search y tinyfish_fetch como herramientas. Cuando necesite buscar algo sobre una libreria, consultar documentacion o verificar un formato de configuracion, buscara en la web y obtendra las paginas relevantes automaticamente.
La latencia de busqueda es tipicamente de 1-3 segundos. Fetch puede tardar unos segundos mas dependiendo de la pagina. Ambas herramientas usan tiempos de espera sensatos por defecto (10s para search, 150s para fetch).
Ahorro de tokens
TinyFish Fetch elimina la navegacion, scripts y contenido repetitivo de las paginas antes de devolver el contenido. Tu modelo procesa el contenido real del articulo, no tres kilobytes de banners de consentimiento de cookies y enlaces de pie de pagina. Esto reduce significativamente el uso de tokens por cada fetch.
Usar TinyFish con Hermes Agent
Hermes Agent de Nous Research tiene una herramienta de busqueda web integrada, pero TinyFish te da mas control sobre los resultados de busqueda y anade obtencion limpia de paginas que Hermes no tiene de serie.
Hay tres formas de conectar TinyFish a Hermes:
Opcion 1: Servidor MCP
TinyFish ejecuta un servidor MCP en https://mcp.tinyfish.ai. Anadelo a tu configuracion MCP de Hermes:
{
"mcpServers": {
"tinyfish": {
"url": "https://mcp.tinyfish.ai"
}
}
}Esto da a Hermes acceso a Search y Fetch a traves del protocolo MCP estandar. El agente las ve como herramientas nativas.
Opcion 2: Habilidad de agente (Skill)
Instala la habilidad de TinyFish desde el cookbook:
npx skills add github.com/tinyfish-io/tinyfish-cookbook --skill use-tinyfishEsto ensena a Hermes cuando usar Search vs Fetch vs Agent, y como llamarlas correctamente. La habilidad incluye logica de decision — usar search para encontrar URLs, fetch para leer paginas conocidas, y escalar a agent solo cuando se necesita automatizacion interactiva del navegador.
Opcion 3: Wrapper CLI
Si prefieres integracion basada en shell, instala el CLI:
npm install -g @tiny-fish/cli
tinyfish auth loginEntonces Hermes puede llamar a tinyfish search query "..." y tinyfish fetch content get <urls> a traves de su acceso al terminal. El CLI escribe resultados en el sistema de archivos en vez de pasarlos por el contexto del modelo, lo que mantiene bajo el uso de tokens.
Cual opcion elegir
MCP es la mas limpia si tu version de Hermes lo soporta. La opcion de skill funciona bien si quieres que el agente entienda la jerarquia de herramientas (search primero, fetch segundo, agent al final). CLI es el respaldo que funciona en todas partes.
Usar TinyFish con OpenClaw y otros agentes
Los mismos patrones aplican a OpenClaw, OpenCode, Claude Code, Cursor, Codex y cualquier otro agente de codificacion que soporte MCP, habilidades o acceso al shell.
MCP para cualquier agente
La URL del servidor MCP es la misma sin importar que agente uses:
{
"mcpServers": {
"tinyfish": {
"url": "https://mcp.tinyfish.ai"
}
}
}Esto funciona con Claude Code, Cursor, Codex, ChatGPT desktop y cualquier cliente compatible con MCP. Ponlo en tu configuracion y reinicia.
API REST para integraciones personalizadas
Si estas construyendo algo personalizado o tu agente no soporta MCP, usa los endpoints REST directamente:
# Busqueda
curl "https://api.search.tinyfish.ai?query=docker+compose+healthcheck" \
-H "X-API-Key: $TINYFISH_API_KEY"
# Fetch
curl -X POST https://api.fetch.tinyfish.ai \
-H "X-API-Key: $TINYFISH_API_KEY" \
-H "Content-Type: application/json" \
-d '{"urls": ["https://docs.docker.com/compose/how-tos/startup-order/"]}'Ambos endpoints devuelven JSON. Search te da resultados clasificados con titulos, snippets y URLs. Fetch te da el contenido limpio de la pagina mas metadatos (titulo, idioma, autor, fecha de publicacion).
SDKs para uso programatico
pip install tinyfishfrom tinyfish import TinyFish
client = TinyFish() # lee TINYFISH_API_KEY del entorno
# Busqueda
results = client.search.query("best React state management 2026")
# Fetch
content = client.fetch.content.get(
urls=["https://tanstack.com/query/latest"],
format="markdown"
)npm install @tiny-fish/sdkimport { TinyFish } from "@tiny-fish/sdk";
const client = new TinyFish(); // lee TINYFISH_API_KEY del entorno
// Busqueda
const results = await client.search.query("best React state management 2026");
// Fetch
const content = await client.fetch.content.get({
urls: ["https://tanstack.com/query/latest"],
format: "markdown",
});El TinyFish Cookbook
El TinyFish Cookbook es una coleccion de proyectos listos para usar construidos sobre TinyFish. Algunos son realmente utiles:
| Proyecto | Que hace |
|---|---|
| viet-bike-scout | Comparacion de precios de alquiler de motos en ciudades vietnamitas |
| openbox-deals | Agregador de ofertas de productos reacondicionados en 8 tiendas |
| competitor-scout-cli | CLI en lenguaje natural para investigar precios de la competencia |
| silicon-signal | Rastreador de la cadena de suministro de semiconductores |
| code-reference-finder | Encuentra ejemplos de uso real de fragmentos de codigo en GitHub y Stack Overflow |
| tinyskills | Genera guias SKILL.md desde documentacion, GitHub y blogs de desarrolladores |
El code-reference-finder es al que mas vuelvo. Pegas una firma de funcion, y busca en GitHub y Stack Overflow ejemplos de uso real. Ahorra mucho tiempo de “como usa nadie esta API realmente”.
El cookbook tambien incluye la habilidad use-tinyfish que ensena a cualquier agente de codificacion la herramienta correcta a usar. Cubre la escalera de decision: search para encontrar URLs, fetch para leer paginas, agent para tareas interactivas del navegador, y browser para control CDP raw.
Explorar el TinyFish CookbookPrecios y limites de tasa
El nivel gratuito cubre Search y Fetch con limites generosos:
| Endpoint | Coste | Limite de tasa gratuito |
|---|---|---|
| Search | Gratis | 30 peticiones/min |
| Fetch | Gratis | 150 URLs/min |
| Agent | 1 credito/paso | 2 ejecuciones simultaneas |
| Browser | 1 credito/4 min | 5 sesiones simultaneas |
Los endpoints Agent y Browser consumen creditos. Obtienes 500 creditos gratis al registrarte, y los planes de pago empiezan en $13/mes por 1.650 creditos. Para uso con agentes de codificacion, Search y Fetch son todo lo que necesitas, y esos son gratis.
Los fetches fallidos no cuentan contra tu cuota. Si una URL devuelve un error, no pagas por ella.
Comparacion con alternativas
TinyFish no es la unica opcion para dar acceso web a los agentes. Asi se compara:
| Caracteristica | TinyFish Fetch | Firecrawl | Fetch nativo LLM | Playwright manual |
|---|---|---|---|---|
| Renderizado JavaScript | Si (Chromium real) | Si | No (solo HTML estatico) | Si |
| Extraccion limpia de contenido | Si | Si | HTML raw | Manual |
| Stealth/anti-bot | Integrado | Variable | No | Configuracion manual |
| Nivel gratuito | Si (Search + Fetch) | Limitado | Depende del proveedor | Pagas por computacion |
| Optimizacion de tokens | Elimina basura | Elimina basura | HTML completo | Manual |
| Batch multi-URL | Hasta 10 URLs/llamada | Variable | No | Manual |
La ventaja principal de TinyFish sobre montar Playwright tu mismo es que no gestionas instancias de navegador, rotacion de proxies o deteccion anti-bot. La ventaja sobre el fetch nativo del LLM es el renderizado JavaScript — la mayoria de sitios de documentacion modernos son SPAs que devuelven shells vacios sin el.
Lo que me gusta y lo que no
He estado usando TinyFish a traves de Pi durante unas semanas. Aqui va la opinion honesta.
Lo que funciona bien: Los resultados de busqueda son limpios y rapidos. Fetch realmente renderiza SPAs correctamente, lo que importa para sitios de documentacion basados en React (te miro a ti, Next.js y Docusaurus). El nivel gratuito es lo suficientemente generoso para uso diario con agentes de codificacion. El ahorro de tokens por contenido limpio es real — mi uso de tokens por sesion bajo de forma notable despues de cambiar del fetching de HTML raw.
Lo que podria mejorar: El endpoint Fetch puede ser lento en paginas pesadas (5-10 segundos para sitios con mucho JavaScript). Search ocasionalmente devuelve resultados desactualizados para eventos muy recientes — no es en tiempo real como Google. Y los endpoints Agent/Browser, aunque potentes, se vuelven caros rapido si necesitas automatizacion interactiva.
En resumen: Para dar a tu agente de codificacion la capacidad de leer documentacion actual y buscar en web, el nivel gratuito de Search + Fetch es dificil de superar. Lo tengo conectado a Pi a traves de pi-tinyfish, y planeo anadir el servidor MCP a mi configuracion de Hermes despues.
Siguientes pasos
- Obtener una clave API gratuita de TinyFish — sin tarjeta de credito
- Instalar pi-tinyfish para Pi coding agent
- Leer el TinyFish Cookbook para ideas de proyectos y la habilidad del agente
- Documentacion de TinyFish para la referencia completa de la API
- Guia de configuracion de Pi coding agent si aun no has instalado Pi
- Guia de configuracion de Hermes Agent para instalacion y configuracion de Hermes


